笔记
本文最后更新于:15 天前
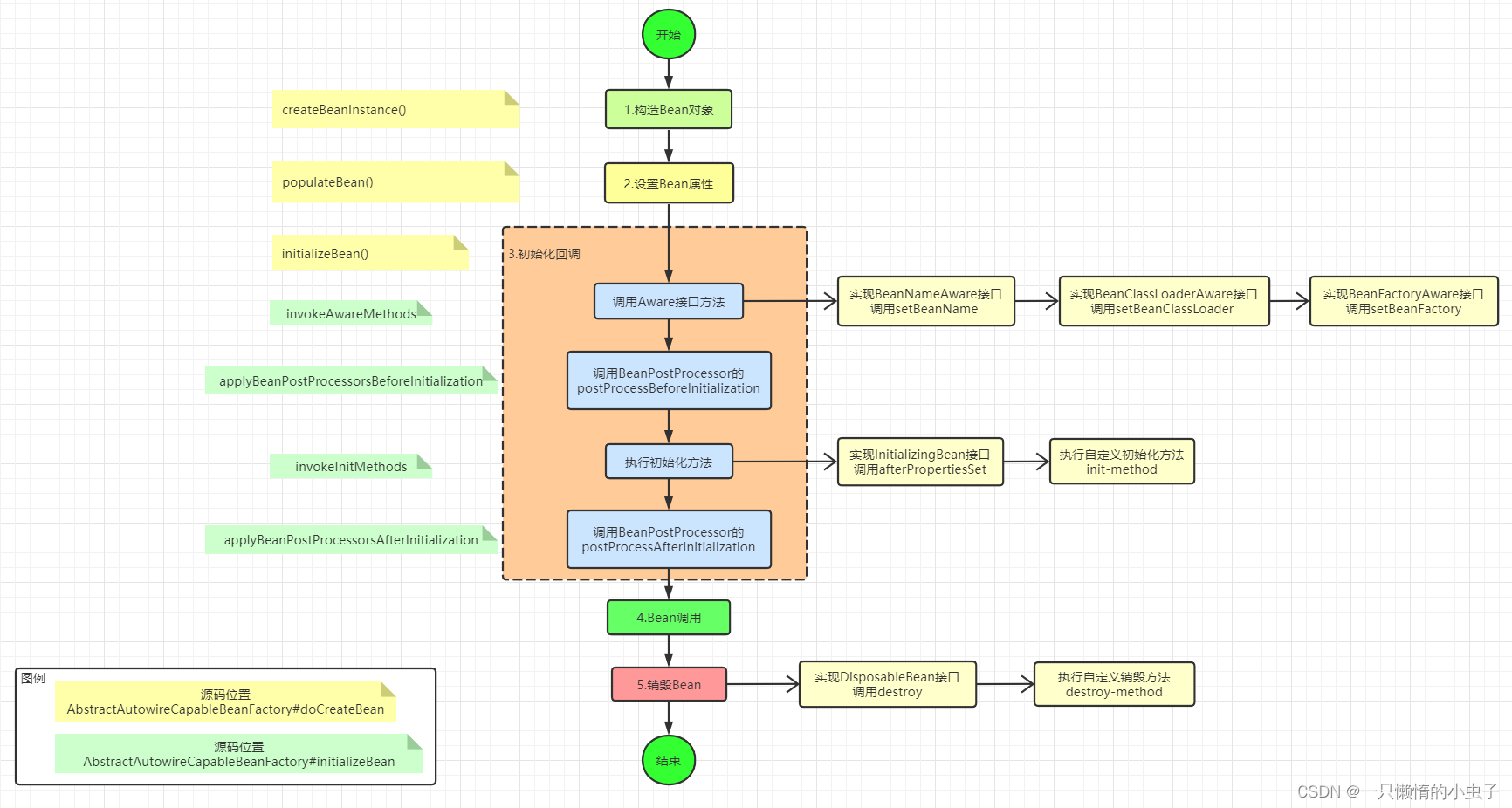
Bean的生命周期
一个Bean的生命周期分为四个阶段:实例化(Instantiation)、 属性设置(populate)、初始化(Initialization)、销毁(Destruction)
实例化(反射),设置bean属性、检查awre接口,beanpostprocesser前置处理、初始化、后置处理、使用、销毁
Bean的六种作用域
singleton: 在IoC容器中只有一份实例,获取Bean(指使用ApplicationContext.getBean()等方法获取)和装配Bean(即使用@Autowired注入),获取到的都是同一个对象.
prototype: 每次对该作用域下的Bean的请求都会创建新的实例,获取Bean(指使用ApplicationContext.getBean()等方法获取)和装配Bean(即使用@Autowired注入),获取到的都是新的对象.
request(请求作用域): 一次http请求中会生成一个新的Bean实例类似于prototype
session(会话作用域): 在http session中定义一个Bean实例
application(全局作用域): 在⼀个http servlet Context中,定义⼀个Bean实例
websocket(HTTP WebSocket作用域): 在一个HTTP WebSocket生命周期中,定义一个Bean实例
什么是AOP:
AOP,一般称为面向切面编程,作为面向对象的一种补充,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect),切面将那些与业务无关,却被业务模块共同调用的逻辑提取、并封装起来,减少了系统中的重复代码,降低了模块间的耦合度,同时提高了系统的可维护性。可用于权限认证、日志、事务处理等。
AOP代理:
代理指为一个目标对象提供一个代理对象,并由代理对象控制对目标对象的引用,使用代理对象,是为了在不修改目标对象的基础上,增强目标对象的业务逻辑。
AOP代理主要分为静态代理和动态代理。
静态代理会为每一个业务Bean增强都提供一个代理类,由代理类来创建代理对象, 而动态代理并不存在代理类,代理对象是通过动态字节码技术,在程序运行时直接动态生成代理对象( 反射)。
静态代理的代表为AspectJ;动态代理主要有两种方式,JDK动态代理和CGLIB动态代理。
**jdk代理** :JDK动态代理要求该业务Bean必须要有实现的接口,通过和该业务Bean--即目标对象,实现相同的接口保证功能一致。
cglib代理 : CGLib动态代理是通过继承该业务Bean–即目标对象,来保证功能一致,即,生成目标对象的子类, 这个子类对象就是代理对象。
- @Before 前置通知:目标方法之前执行
- @After 后置通知:目标方法之后执行(始终执行)
- @AfterReturning 返回通知:执行方法结束前执行(异常不执行)
- @AfterThrowing 异常通知:出现异常的时候执行
- @Around 环绕通知:环绕目标方法执行
Spring5: (Spring4 @Around在@After之前)

Spring 是怎么解决循环依赖的?
Spring 内部通过 3 级缓存来解决循环依赖。
第一级缓存:singletonObjects ,存放已经经历完整生命周期的 Bean 对象
第二级缓存:earlySingletonObjects ,存放早期暴露出来的 Bean 对象,Bean 的生命周期未结束(属性还未填充完成),就是 bean 已经创建了,但是属性还没有初始化。类似于房子买好了,但是家具还没有搬进来。
第三级缓存:singletonFactories 存放可以生成 Bean 的工厂。
只有单例的 bean 会通过三级缓存提前暴露来解决循环依赖问题,而非单例的 bean ,每次从容器中获取的都是一个新的对象,都会重新创建,所以非单例的 bean 是没有缓存的,不会将其放到三级缓存中。
A/B 两个对象在三级缓存中的迁移说明:
1、A 创建过程需要 B ,于是 A 将自己放到三级缓存中,去实例化 B
2、B 实例化的时候发现需要A,于是 B 先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了A,然后把三级缓存里面的A放到二级缓存里面,并删除三级缓存里面的A
3、B顺利初始化完毕,将自己放到一级缓存里面(此时 B 中的 A 依然是创建中状态),然后回来接着创建A,此时B已经创建结束,直接冲一级缓存中拿到B,然后完成创建,并将 A 自己放到一级缓存里面。
实际开发中创建索引时有哪些优化
1、索引覆盖:索引覆盖指索引中包含了要查询的全部字段,在查询时,从索引中即能得到查询结果,无需读取记录数据。当使用的是聚簇索引时,无需读取记录数据那么就避免了回表操作。
避免回表:回表指使用非聚簇索引时,一次select需要执行两次查询:先从非聚簇索引树中查到目标记录的主键,在根据主键值在聚簇索引树中查到真正的记录数据。
尽量使用主键查询查找数据,因为主键默认建立索引,通过主键查询信息时不仅会用到索引,而且不会回表。
2、在模糊查询中(like),A% 前缀查询可以使用索引,%A中缀和%A%后缀查询都不能使用索引。
Redis 数据类型
五种redis的类型与java的数据类型的类比
- string –> String
- hash –> Hashmap
- list –> LinkList
- set –> HashSet
- zset –> TreeSet
String类型应用场景
1、大型应用中会进行分表操作,为保证主键唯一并且递增。
可以使用到Redis的String数据类型,对key自增,作为数据的主键。
2、对于热门商品,过了指定时间后不在热门的情况。
对Redis的key设置过期时间。
3、博客主页高频信息显示控制,博主的粉丝数、关注数、获得的赞等热点数据,存入Redis。
hash类型应用场景
1、电商网站购物车的设计与实现。

2、Hash实现抢购,限购发放优惠券,激活码等。
- 以商家id作为key
- 将参与抢购的商品id作为field
- 将参与抢购的商品数量作为对应的value
- 抢购时使用降至的方式控制产品数量
list类型应用场景
1、博客主页高频信息显示控制,博主的粉丝用户、关注用户等按照用户的关注顺序进行展示。
list的数据具有顺序的特征,以博主id为key存入粉丝的id。
2、微信朋友圈点赞,要求按照点赞顺序显示点赞好友信息。
set类型应用场景
1、共同好友
求两个集合的交、并、差集
sinter key1 [key2] //交集
sunion key1 [key2] //并集
sdiff key1 [key2] //差集(key1有但是key2没有的)
求两个集合的交、并、差集并存储到指定集合中
sinterstore destination key1 [key2]
sunionstore destination key1 [key2]
sdiffstore destination key1 [key2]
2、黑白名单
- 基于经营战略设定问题用户发现、鉴别规则
- 周期性更行满足规则的用户黑名单,加入set集合
- 用户行为信息达到后与黑名单进行比比对,确认行为去向
- 黑名单过滤IP地址:应用于开放游客访问权限的信息源
- 黑名单过滤设备信息:应用于限定访问设备的信息源
- 黑名单过滤用户:应用于基于访问权限的信息源
zst类型应用场景
1、建立排序依据
- 获取数据对应的索引(排名)
zrank key member //正数第几位
zrevrank key member //倒数第几位
Redis服崩了,内存中的数据该如何恢复
Redis中的数据存在内存中,如果突然宕机,那么内存中的数据将全部丢失。最好的方式是对数据进行持久化,并能当宕机的时候能快速恢复。在Redis中有如下两种持久化方式,rdb快照和aof日志
RDB
rdb就是对当前数据库的状态做一个快照,将某个阶段的数据通过二进制文件保存下来。你可以类比照相。内存中的数据越多,生成快照的时候就越长,同时将快照写入磁盘耗费的时间也越长。
save:在主线程中执行,会导致阻塞
bgsave:主线程fork出一个子进程负责创建rdb文件,不会阻塞主线程
COW机制(Copy-On-Write)
数据段由很多操作系统的页面组成,当父进程对其中一个页面的数据进行修改时,会将被共享的页面复制一份分离出来,然后对这个复制的页面进行修改。这时子进程相应的页面是没有变化的,还是进程产生时的数据。子进程中的数据一直没有变化.
AOF
当我们每次执行一条命令的时候,把对应的操作记到aof日志中,当redis宕机的时候我们只要重放日志就能恢复数据。
先执行命令,再写日志。
提供了三种写aof日志的方式:
always:同步写回,写命令执行完就同步到磁盘
everysec:每秒写回,每个写命令执行完,只是先把日志写到aof文件的内存缓冲区,每隔1秒将缓冲区的内容写入磁盘
no:操作系统控制写回,每个写命令执行完,只是先把日志写到aof文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回到磁盘
AOF日志重写
读取读取内存中的最新值,然后保存对应的命令。
rpush list 1
rpush list 2
rpush list 3
rpush list 1 2 3
数据库和redis缓存不一致怎么解决
1.给缓存数据设置过期时间
2.缓存延时双删
- 先淘汰缓存
- 再写数据库
- 休眠1秒,再淘汰缓存(这么做,可以将1秒内所造成的缓存脏数据,再次删除。)
3.删除缓存重试机制
若休眠后删除缓存失败了,则多删除几次,保证删除缓存成功,所以可以引入删除缓存重试机制。
(1)更新数据库数据;
(2)缓存因为种种问题删除失败
(3)将需要删除的key发送至消息队列
(4)自己消费消息,获得需要删除的key
(5)继续重试删除操作,直到成功
4.读取biglog异步删除缓存
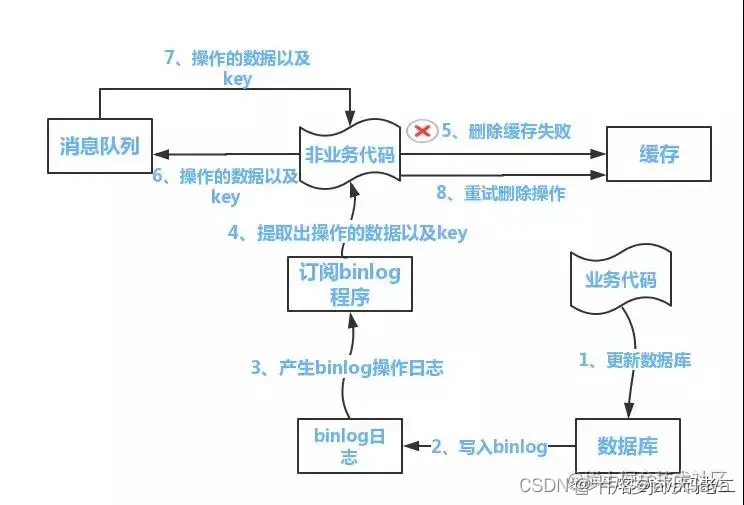
流程如下图所示:
(1)更新数据库数据
(2)数据库会将操作信息写入binlog日志当中
(3)订阅程序提取出所需要的数据以及key
(4)另起一段非业务代码,获得该信息
(5)尝试删除缓存操作,发现删除失败
(6)将这些信息发送至消息队列
(7)重新从消息队列中获得该数据,重试操作。